
Web Scraping with Selenium in Python
Contents
Selenium, a versatile automation framework, offers developers a wide range of uses. One of the most common usages of Selenium for developers is doing automated testing for web applications. As it offers a wide range of functionalities to simulate user interactions with the browser and automate browser actions, you can utilize it to automate other tasks besides automated testing to increase your efficiency and productivity.
One example is using Selenium to scrape websites. In today’s digital age where data is the key to making informed decisions, we often find ourselves in need of data from various websites. Therefore, web scraping has become an essential skill for developers looking to leverage the vast amount of information available online. In this article, let’s explore how to use Selenium to scrape websites and extract valuable data from them.
What is Selenium

Selenium is a widely-used browser automation tool that has been around since 2004. It consists of Selenium WebDriver, Selenium IDE, and Selenium Grid. Each of them complements the other to carry out automated tests on different browsers and environments, with Selenium WebDriver being the core of the automated testing ecosystem.
Being a mature automation tool, it supports a wide range of web browsers and programming languages including non-mainstream ones like Haskell, Perl, Dart, and Pharo Smalltalk. It is also highly extensible—a large ecosystem of third-party plugins and frameworks that can enhance its functionality are available, which makes it very useful in various use cases.
As Selenium is an open-source project, its growth is contributed by the support of the community. Besides efforts by individual contributors like programmers, designers, and QA engineers, it is also sponsored by established companies like BrowserStack, Lambdatest, Sauce Lab, and more.
How to Use Selenium for Web Scraping
Selenium supports several browser engines including Chrome, Firefox, Safari, Microsoft Edge, and Opera. Although there are custom capabilities and unique features for each browser, the main functionalities are available for every one of them.
In this article, we will show how to use it on Chrome to scrape a job board. That said, you can follow the same steps to use it on other browsers too.
Step 1. Install the Selenium Package
In your project directory, run the command below to install the Selenium package so that it can be used in your Python code.
pip install selenium
Step 2. Install Browser Drivers
To automate the browsers, you need the browser drivers. There are a few methods to install the drivers, with the easiest method being downloading them from the official website and configuring Selenium to use the specified drivers using one of the options below:
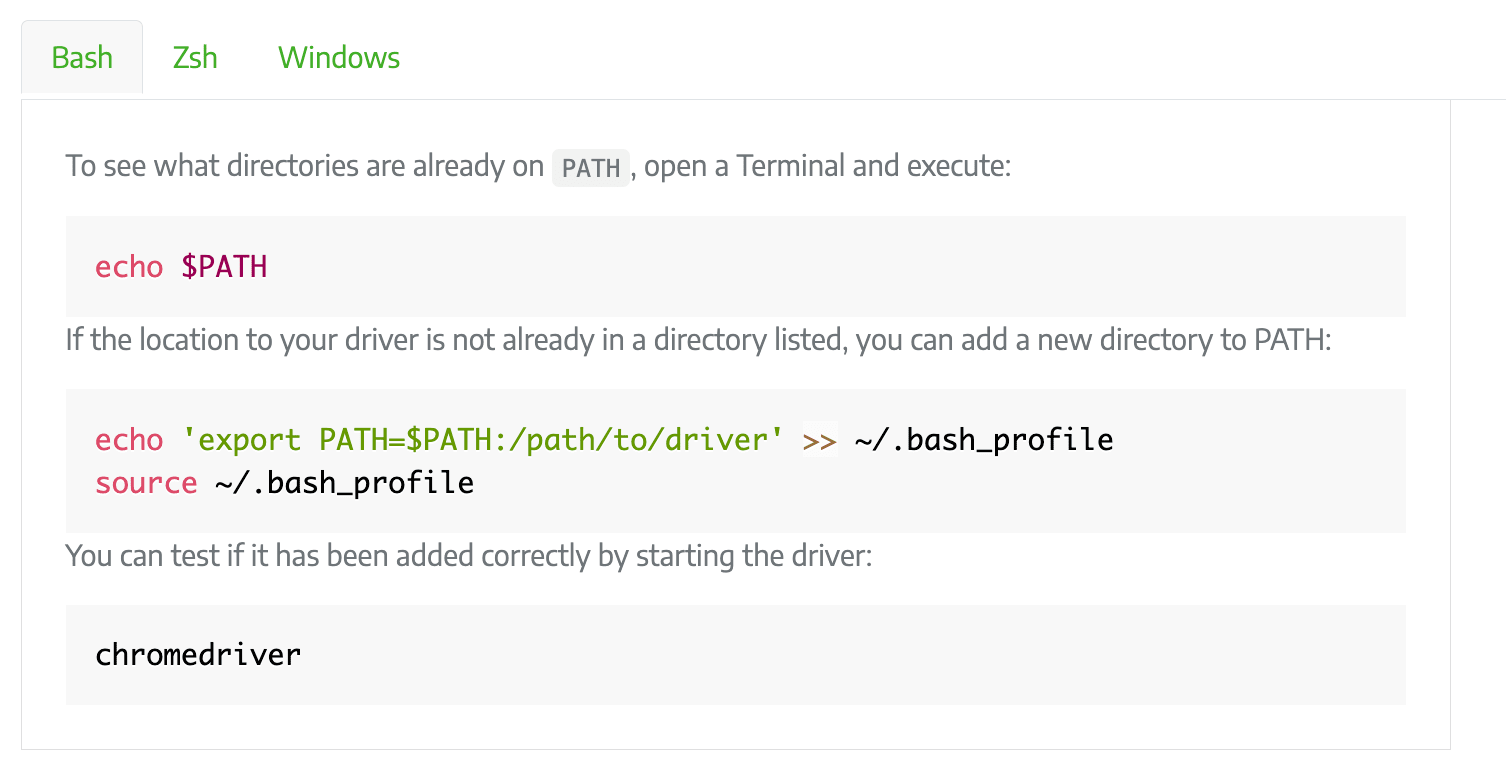
Option 1: Save the Driver Location in the PATH Environment Variable
You can place the drivers in a directory that is already listed in PATH or add the drivers’ location to PATH. To save them to the PATH environment variable, run the commands below in the Terminal or Command Prompt:
In your code, import the Selenium package and create a new instance of the driver:
from selenium import webdriver
driver = webdriver.Chrome()
Option 2: Specify the Driver Location in Your Code
You can also hardcode the driver’s location to save the hassle of figuring out the environment variables on your system. However, this might make the code less flexible as you will need to change the code to use another browser.
In your code, import the Selenium package. Then, specify the location of the driver and create a new instance of the driver:
from selenium import webdriver
driver_path = '/path/to/chromedriver'
driver = webdriver.Chrome(executable_path=driver_path)
Step 3. Navigate to the Target Website
After completing the setup, we can start writing code to interact with the browser! To scrape data from a website, visit the URL using the get() method:
driver.get("https://playground.browserbear.com/jobs/")
Step 4. Locate Elements
We must let Selenium know which HTML element it should get the data from. There are several ways to locate an HTML element from a web page. You need to identify the elements that you want to extract the data from and inspect them to determine which of the locator strategies to use for locating them.
You can use the following:
- Attributes like name, ID, class name, and tag name
Example:button = driver.find_element(By.CLASS_NAME, "button") - Link text
Example:link = driver.find_element(By.LINK_TEXT, 'link') - CSS selectors
Example:content = driver.find_element(By.CSS_SELECTOR, 'p.content') - XPath expression
Example:form = driver.find_element(By.XPATH, "/html/body/form[1]")
Let’s locate the job cards and the elements within them as highlighted in the screenshot:
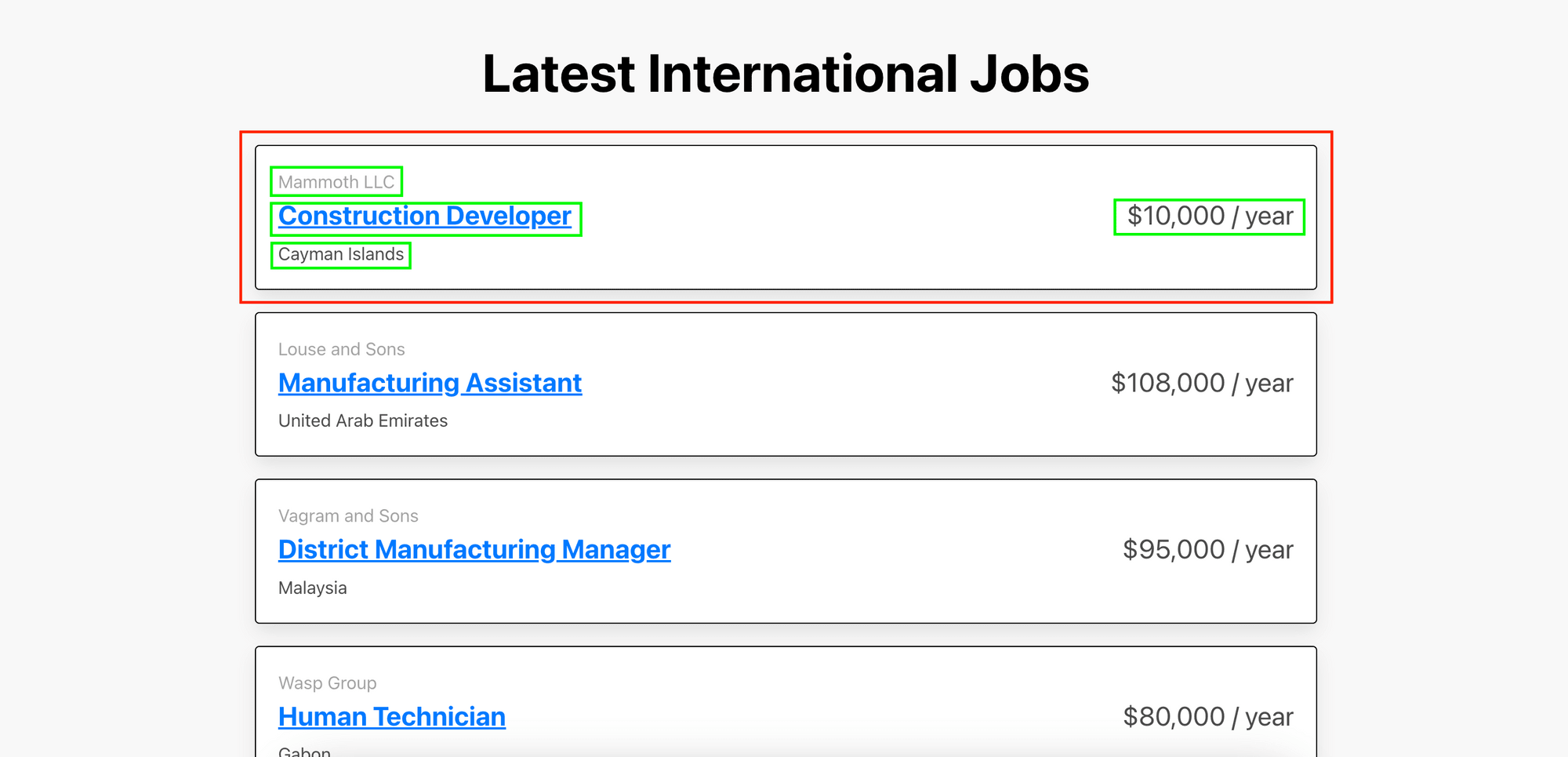
As the elements are contained within a card, we need to locate the parent card (job_card) first. Then, loop through each card to find the child elements.
job_card = driver.find_elements(by=By.TAG_NAME, value="article")
for card in job_card:
job_element = card.find_element(by=By.TAG_NAME, value="a")
company = card.find_element(by=By.CLASS_NAME, value="company")
location = card.find_element(by=By.CLASS_NAME, value="location")
salary = card.find_element(by=By.CLASS_NAME, value="salary")
🐻 Bear Tips : You can use more than one type of locator strategy in the same code. Choose them based on what's available in the HTML code.
Step 5. Extract Data
Once you have located the desired elements, you can extract data from them using the text property. For links, use the get_attribute() method to get the href attribute.
job_card = driver.find_elements(by=By.TAG_NAME, value="article")
for card in job_card:
job_element = card.find_element(by=By.TAG_NAME, value="a")
job_title = job_element.text
link = job_element.get_attribute("href")
company = card.find_element(by=By.CLASS_NAME, value="company").text
location = card.find_element(by=By.CLASS_NAME, value="location").text
salary = card.find_element(by=By.CLASS_NAME, value="salary").text
# Print the extracted text and link
print("Job Title:", job_title, " - ", link)
print("Company:", company)
print("Salary: ", salary)
print("Location: ", location)
print()
Step 6. Quit the Web Driver
After scraping the data, quit the web driver.
driver.quit()
Here’s the full code:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://playground.browserbear.com/jobs/")
job_card = driver.find_elements(by=By.TAG_NAME, value="article")
for card in job_card:
job_element = card.find_element(by=By.TAG_NAME, value="a")
job_title = job_element.text
link = job_element.get_attribute("href")
company = card.find_element(by=By.CLASS_NAME, value="company").text
location = card.find_element(by=By.CLASS_NAME, value="location").text
salary = card.find_element(by=By.CLASS_NAME, value="salary").text
# Print the extracted text and link
print("Job Title:", job_title, " - ", link)
print("Company:", company)
print("Salary: ", salary)
print("Location: ", location)
print()
driver.quit()
Advanced: Interacting with the Elements to Scrape More Data
Each job from the job board has a link that shows more information about the job. This is what you see when you click on it:

To scrape these details, you can click on the links using click() and find the target elements using similar methods. Then, use driver.back() to go back to the main page and continue with the next job in the list.
...
for card in job_card:
job_element = card.find_element(by=By.TAG_NAME, value="a")
...
job_element.click() # go to the link
applicant = driver.find_element(by=By.CLASS_NAME, value="applicants").text
driver.back()
# Print the extracted text and link
print("Job Title:", job_title, " - ", link)
print("Company:", company)
print("Salary: ", salary)
print("Location: ", location)
print("Applicants: ", applicant)
print()
...
Advantages vs. Disadvantages
While Selenium does a good job in web scraping and other automated web tasks, it has some advantages and disadvantages. Let's take a closer look at both of them:
Advantages
- Open-Source - As mentioned previously, Selenium is an open-source project which growth is contributed by the community. This means that it's free to use while having great support from the community.
- Rich Element Selection Options - Selenium provides a wide range of methods to locate elements on a web page, including by ID, class name, CSS selector, and XPath. This allows you to target desired elements precisely no matter how the website is coded.
- Flexibility and Extensibility - Selenium offers APIs for multiple programming languages including Python, Java, C#, and more. This allows you to work with various programming languages and transfer Selenium's extensive functionalities across different environments.
Disadvantages
- Setup and Configuration - Setting up Selenium and its associated web drivers can be complex, especially for beginners. If it’s not configured correctly, it may cause compatibility issues and waste your time fixing it.
- Learning Curve - Selenium has a steeper learning curve compared to simpler scraping tools, which might require more time to get yourself familiarized with it.
- Limited Scalability - Selenium requires a web browser and associated drivers, which consume system resources. Therefore, running multiple instances of Selenium concurrently can be resource-intensive and may not be feasible for large-scale scraping operations.
Other Selenium Alternatives
If the disadvantages above make you hesitate to use Selenium for web scraping, you can consider using Browserbear. It has a user-friendly and intuitive interface which simplifies the process of creating and executing an automated web scraping task. Moreover, being a cloud-based solution, it provides effortless scalability, which means you can expand your web scraping task as needed easily without having to take care of the infrastructure.
The embedded task below is an example of using Browserbear to do the same job:
You can duplicate it to start scraping immediately or follow the instructions in How to Scrape Data from a Website Using Browserbear to learn how to do it step-by-step.
Conclusion
Utilizing automation is a good way to free up our time for more important tasks and increase productivity. No matter you are using Selenium which requires coding or Browserbear which uses an intuitive interface, web scraping is just one of the examples of how automation can significantly benefit developers. If you haven't incorporated automation in your workflow, you are doing extra work without realizing it. So, start automating now!
