
Web Scraping with Playwright in Python
Contents
Python is often the programming language of choice when it comes to data-related tasks. It provides a rich ecosystem of libraries and tools specifically designed for this type of task, from the beginning (data acquisition) to the end (visualization). In each stage of the process, different libraries can be used.
In the stage of data acquisition, you can collect data from various sources including public datasets, existing databases, surveys, etc. Besides that, you can also extract data from websites programmatically if they don't provide an API. This is especially useful when the amount of data is huge (which is common for data-related tasks) as doing it manually is unfeasible.
In this article, we will learn how to scrape data from a website using the Playwright library in Python. We will scrape information like the job title, company name, location, and salary from this job board:
What is Playwright

Playwright is a relatively new browser automation tool that was released by Microsoft in 2020. It helps developers to automate web browsers such as Chrome, Firefox, Safari, and Microsoft Edge. Not only that the desktop versions of these browsers are supported, but it also works on their mobile versions, all with a single API.
The Playwright API provides a method to launch a browser instance for automation. It is available in multiple programming languages including TypeScript, JavaScript, Python, .NET/C#, and Java. Therefore, it is used by developers from various software ecosystems to automate web browsers. Its ability to run multiple instances simultaneously makes it a strong competitor among other automation tools and frameworks. This is especially useful for automated testing. In a single test, you can test scenarios with different contexts that span multiple tabs, origins, and users.
How to Use Playwright for Web Scraping
For the sake of simplicity, we will learn how to use it on Chromium only. That said, you can follow the same steps for other browsers too.
Step 1. Install the Playwright Package
In your project directory, run the command below to install the Playwright package so that it can be used in your Python code:
pip install playwright
Step 2. Install Browser Drivers
You need a browser driver to automate the browser. The command below installs all available browsers (Chromium, Firefox, and WebKit) using the Playwright CLI by default:
playwright install
To install a particular browser (eg. Chromium) only, provide its name as an argument in the command:
playwright install chromium
The installed browsers will be saved into OS-specific cache folders. Therefore, we do not need to specify their location in the code. By default, they will be kept in:
%USERPROFILE%\\AppData\\Local\\ms-playwrighton Windows~/Library/Caches/ms-playwrighton MacOS~/.cache/ms-playwrighton Linux
Next, import Playwright in your Python script and launch the browser:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
Playwright can run synchronously and asynchronously. To run it asynchronously, use async_playwright() instead of sync_playwright() and add await to your code:
with async_playwright() as p:
browser = await p.chromium.launch()
🐻 Bear Tips: The browser runs headlessly by default but you can pass the
headless=Falseflag while launching the browser to see it in action!
Step 3. Navigate to the Target Website
Within the scope of the “with” statement, open a new page and visit the URL of the target website using the goto() method:
page = browser.new_page()
page.goto("https://playground.browserbear.com/jobs/")
Step 4. Locate Elements
There are several ways to locate an HTML element from a web page. You need to identify the elements you want to extract the data from and inspect them to determine which locator strategies to use.
You can use these locator strategies:
- Attributes like alt text, label, placeholder, role, and title
Example:page.get_by_alt_text("screenshot image") - Text
Example:page.get_by_text("Welcome"),page.get_by_text("Hello, World", exact=True) - CSS selectors (use page.locator())
Example:page.locator("css=p.content") - XPath selectors (use page.locator())
Example:page.locator("xpath=/html/body/form[1]")
To locate an element more accurately, you can add arguments like “text=”, “exact=”, etc. For example, page.get_by_text("Hello, World", exact=True) finds the elements that match the string exactly, filtering out partial matches like “hello, world” and “Hello, Worlds”.
When using the page.locator() method, Playwright is able to auto-detect the selector’s type. A selector starting with // or .. is assumed to be an XPath selector. Otherwise, it will be assumed as a CSS selector. Therefore, you can omit the “css=” or “xpath=” prefix (eg. page.locator("p.content")), if you prefer.
Let’s locate the job cards and the elements within them as highlighted in the screenshot below:
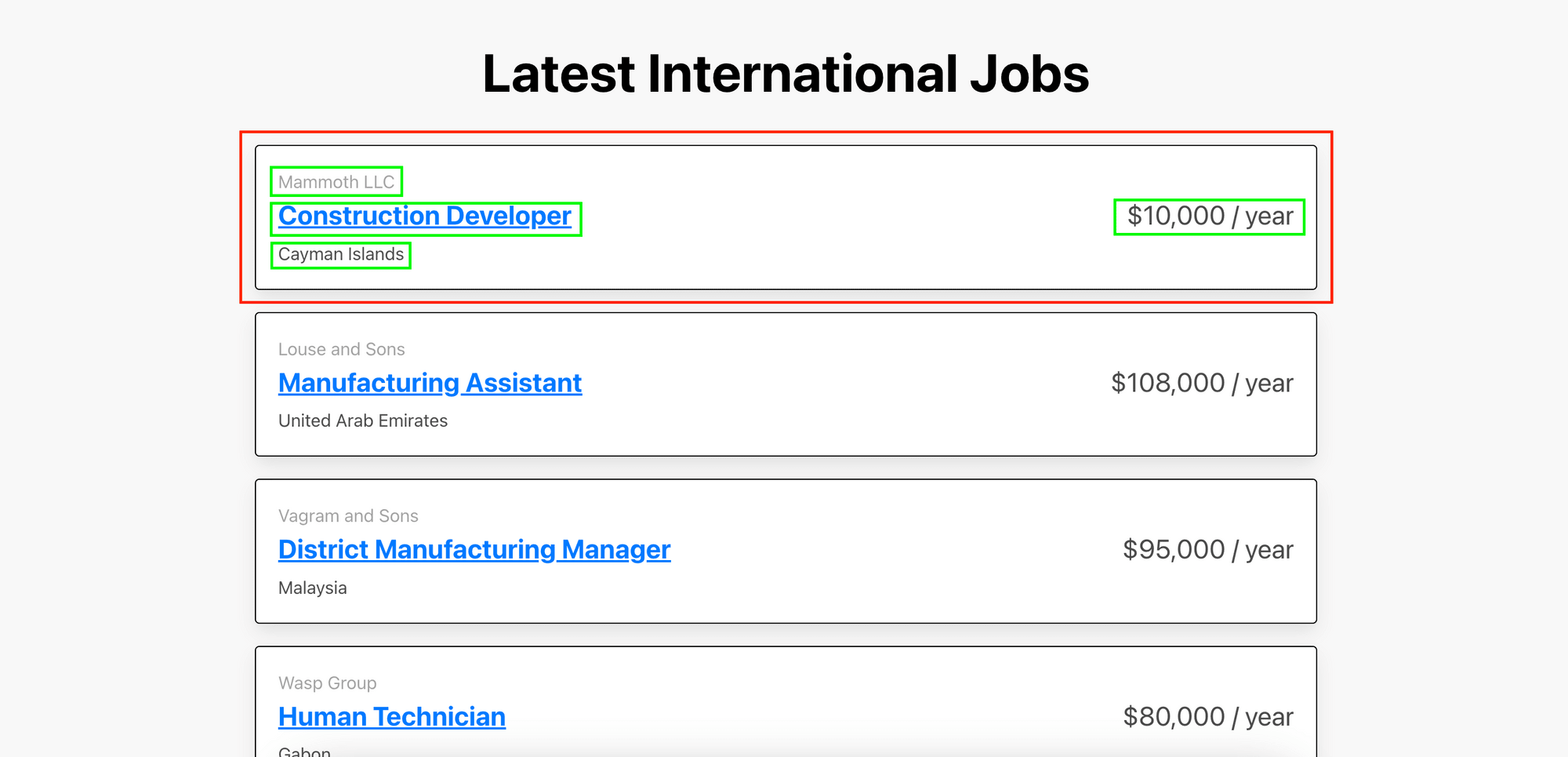
As the elements are contained within a card, we need to locate the parent card (job_card) first. Then, loop through each card to find the child elements.
job_card = page.locator("article").all()
for card in job_card:
job_element = card.locator("a")
company = card.locator(".company")
location = card.locator(".location")
salary = card.locator(".salary")
Step 5. Extract Data
Once you have located the desired elements, you can extract data from them using inner_html(). For links, use the get_attribute() method to get the href attribute.
job_card = page.locator("article").all()
for card in job_card:
job_element = card.locator("a")
job_title = job_element.inner_html()
link = job_element.get_attribute("href")
company = card.locator(".company").inner_html()
location = card.locator(".location").inner_html()
salary = card.locator(".salary").inner_html()
print("Job Title:", job_title, " - ", link)
print("Company:", company)
print("Salary: ", salary)
print("Location: ", location)
print()
Step 6. Close the Browser
When you’re done scraping the data, close the browser.
browser.close()
Here’s the full code:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("https://playground.browserbear.com/jobs/")
job_card = page.locator("article").all()
for card in job_card:
job_element = card.locator("a")
job_title = job_element.inner_html()
link = job_element.get_attribute("href")
company = card.locator(".company").inner_html()
location = card.locator(".location").inner_html()
salary = card.locator(".salary").inner_html()
print("Job Title:", job_title, " - ", link)
print("Company:", company)
print("Salary: ", salary)
print("Location: ", location)
print()
browser.close()
Advanced: Interacting with the Elements to Scrape More Data
Each job from the job board has a link that shows more information about the job. This is what you'll see when you click on it:

To scrape these details, you can click on the links using click() and find the target elements using similar methods. Then, use page.go_back() to go back to the main page and continue with the next job in the list.
...
for card in job_card:
job_element = card.locator("a")
...
job_element.click() # go to the link
applicant = page.locator(".applicants").inner_html()
page.go_back()
company = card.locator(".company").inner_html()
location = card.locator(".location").inner_html()
salary = card.locator(".salary").inner_html()
# Print the extracted text and link
print("Job Title:", job_title, " - ", link)
print("Company:", company)
print("Salary: ", salary)
print("Location: ", location)
print("Applicants: ", applicant)
print()
...
Advantages vs. Disadvantages
While Playwright does a good job in automating data acquisition, it has some advantages and disadvantages. Let's take a closer look at both of them:
Advantages
- Auto-wait APIs - Playwright auto-waits for elements to be ready. Depending on the type of action, Playwright will perform different actionability checks on properties like enabled, attached, visible, etc. before executing the next action. This makes sure that the action can be executed correctly.
- Lean parallelization - Playwright runs in a browser context—an isolated incognito-like session within a browser instance. As multiple browser contexts can be created within a single browser instance, it is relatively cheap to create parallelized, isolated execution environments.
- Flexibility and extensibility - Playwright offers APIs for multiple programming languages including Python, Java, JavaScript, and .NET/C#. This allows you to work with various programming languages and transfer Playwright's extensive functionalities across different environments.
Disadvantages
- Setup and configuration - While Playwright can be executed in CI environments, you need to set up and do some configurations to get it running. This would be overkill for a simple web scraping task.
- Learning curve - Playwright has a steeper learning curve compared to other more straightforward scraping tools. Therefore, it might require more time for you to get familiar with it.
- Challenging for websites with CAPTCHA - It might be difficult to scrape websites that implement CAPTCHA as you will need to use additional packages like 2Captcha and Stealth plugin to solve or bypass it.
Other Playwright Alternatives
No doubt Playwright is a great browser automation tool but there are other easier alternatives, like Browserbear. Browserbear is a browser automation tool with a user-friendly and intuitive interface that simplifies the process of creating and executing an automated task, including scraping data from a website with CAPTCHA. With Browserbear, the CAPTCHA can be solved with just a single step. Moreover, being a cloud-based solution, it offers effortless scalability as the infrastructure is being taken care of for you.
Here’s an example of a Browserbear task that does the same job of scraping data from the job board:
You can duplicate the embedded task above to start scraping immediately or follow the instructions in How to Scrape Data from a Website Using Browserbear to learn how to do it step-by-step.
Conclusion
Data acquisition is crucial in any data-related task and larger data sets often improves its quality no matter what the objective is. However, it is not easy to gather large amounts of data manually. Therefore, you should make use of appropriate tools like Playwright or Browserbear to help you do it easily. If you're interested, sign up for a free Browserbear trial and you can start gathering data effortlessly in no time!
