
Mastering XPath: Using the “following-sibling” and “preceding-sibling” Axes
Contents
XPath, also known as XML Path Language, is an expression language used to navigate and select elements in an XML or HTML document. It provides a way to locate elements on a web page based on their tag name, attributes, position, text content, and more in the document’s hierarchy.
Unlike CSS Selectors that only support one-directional flow for locating an HTML element (from parent to child), XPath supports bidirectional flow—traversal can be both ways.
Besides that, it can also traverse sideways to find siblings of an element. Let's learn how you can do it with the following-sibling:: and preceding-sibling:: axes!
XPath Basics: Understanding XPath Axes
XPath uses a path notation that is similar to URLs to navigate the hierarchical structure of an HTML/XML document for finding an element/node. Each step in the XPath expression is separated by a slash ( “/” or “//” ), which is the fundamental of the many axes available.
In XPath, an axis is used to define the relationships between elements in an HTML/XML document. It allows you to navigate the document structure in a specific direction or pattern and select elements based on their position or relationship to other elements.
The slashes ( “/” or “//” ) traverse down the document to select the child or descendant elements of the current element.
| Axis | Description | Example |
|---|---|---|
| / | Selects all child elements of the current element. | /html/body/h1 - Selects the <h1> element that is a direct child of the <body> element. |
| // | Selects all descendant elements of the current element, regardless of their depth. | /html/body//h3 - Selects all <h3> elements anywhere in the document that are descendants of the <body> element. |
Besides traversing down, you can also traverse the document sideways, using axes like following-sibling:: and preceding-sibling::.
What is the “following-sibling” Axis
In XPath, following-sibling:: is an axis used to select all sibling elements that appear after the current element. By way of comparison, it is like finding the "younger siblings" of the current element in a family tree.
This is the syntax for using the following-sibling:: axis:
/parent/current-element/following-sibling::target
Let’s see some practical examples following the HTML snippet below:
<div>
<p>Element 1</p>
<p>Element 2</p>
<a href="https://www.browserbear.com">Browserbear</a>
<p class="last_paragraph">Element 3</p>
</div>

Suppose you want to select all elements that come after the first <p> element, you can use the following-sibling:: axis with a wildcard (*), as shown in the XPath expression below:
//p[1]/following-sibling::*

If you specifically want to select only the <p> elements, use the following-sibling:: axis with tag name p:
//p[1]/following-sibling::p

The same applies for selecting the <a> element:
//p[1]/following-sibling::a

You can also use a predicate to select an element more precisely. The XPath expression below selects only the <p> elements that follow the first one AND with the class name last_paragraph:
//p[1]/following-sibling::p[@class="last_paragraph"]
Using the XPath expression above, only the third <p> element will be selected.

What is the “preceding-sibling” Axis
On the other hand, the preceding-sibling:: axis is used to select all sibling elements that appear before the current element. Think of it as finding the "older siblings" of the current element in a family tree.
This is the syntax for using the preceding-sibling:: axis:
/parent/current-element/preceding-sibling::target
Let’s use the same HTML snippet for some examples but with the last (third) <p> element as the current element.
To select all elements that come before the last <p> element, you can locate it by its class name and select the preceding siblings using the wildcard:
//p[@class="last_paragraph"]/preceding-sibling::*

Similarly, if you specifically want to select only the <p> elements, specify the tag name after preceding-sibling:::
//p[@class="last_paragraph"]/preceding-sibling::p

It goes the same for the <a> element:
//p[@class="last_paragraph"]/preceding-sibling::a

Besides using the predicate with a class name like the previous example, we can also use other attributes or functions. For example, we can use a function like contains() to find elements that contain specific text.
The XPath expression below finds preceding sibling that is a <p> element and contains the text "1":
//p[@class="last_paragraph"]/preceding-sibling::p[contains(text(), '1')]
This will return only the first <p> element with text “Element 1”.

Example: Using the “following-sibling” and “preceding-sibling” Axes in Selenium (Python)
XPath is one of the most versatile methods to locate an HTML element from a web page when using Selenium. Similar to using any XPath expression to locate an HTML element from a web page, start by navigating to the target URL and find the element using the find_elements() method.
Let’s find the steps preceding and following “Step 3. Navigate to the Target Web Page” from this page:
Get the XPath that refers to "Step 3. Navigate to the Target Web Page" from the browser inspector:
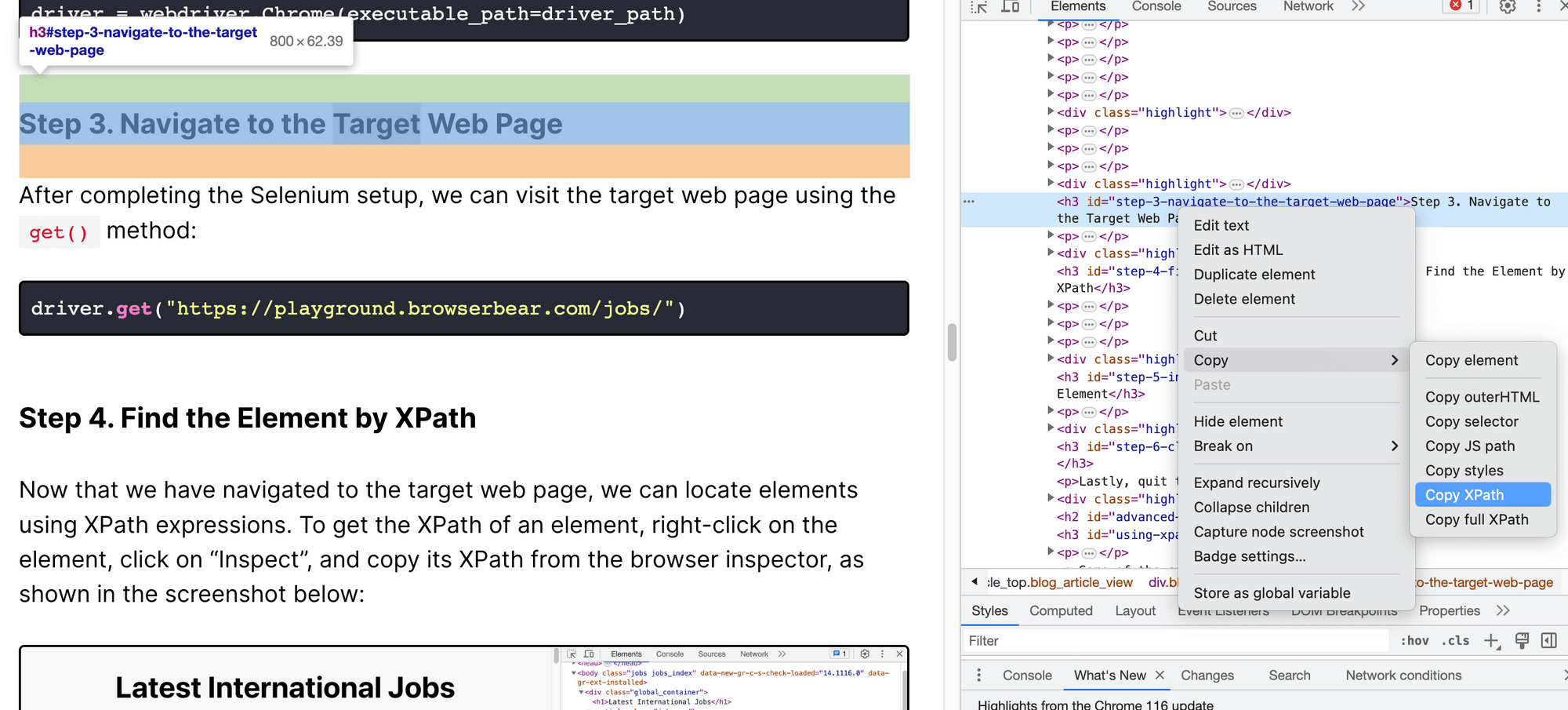
Note: For the ease of locating the element, we're using the <h3> element instead of the <li> element in the content menu.
This is the XPath:
//*[@id="step-3-navigate-to-the-target-web-page"]
To find the steps before Step 3, use the preceding-sibling:: axis to find preceding <h3> elements that contain the word “Step”:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
# Navigate to the target web page
driver.get("https://www.browserbear.com/blog/how-to-find-elements-by-xpath-in-selenium")
# Find element
steps = driver.find_elements(By.XPATH, "//*[@id='step-3-navigate-to-the-target-web-page']/preceding-sibling::h3[contains(text(), 'Step')]")
for step in steps:
print(step.text)
# Step 1. Install the Selenium Package
# Step 2. Install the Browser Drivers
To find steps after Step 3, change the axis to following-sibling:::
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
# Navigate to the target web page
driver.get("https://www.browserbear.com/blog/how-to-find-elements-by-xpath-in-selenium")
# Find element
steps = driver.find_elements(By.XPATH, "//*[@id='step-3-navigate-to-the-target-web-page']/following-sibling::h3[contains(text(), 'Step')]")
for step in steps:
print(step.text)
# Step 4. Find the Element by XPath
# Step 5. Interact with the Element
# Step 6. Close the Web Driver
XPath vs. CSS Selectors: Which is Better
Both XPath and CSS Selectors are commonly used to locate an HTML element on a web page. To decide which one to use, here are some factors that you should consider:
- Selector availability - CSS Selectors can locate an element directly using its ID, class, name, and other attributes. However, they might not always be available. In this case, you can use XPath to locate an HTML element based on its position in the document hierarchy.
- Readability - Compared to using an absolute XPath that starts from the root element of the document and navigates down the hierarchy of the elements until the target element is found, CSS selectors are shorter. This will keep your code cleaner and easier to read.
- Project requirements - Not all HTML elements can be located using CSS selectors. For example, you might need to find an element based on its text content in some cases. However, you can’t match an HTML element based on its text content using a CSS selector but you can do it in XPath, eg.
//h1[text()='Welcome']. - Directional flow - CSS Selectors support one-directional flow for locating an HTML element, traversing elements from parent to child. On the other hand, XPath supports bidirectional flow and sideways traversal.
While CSS Selectors are simpler and easier to use, XPath is more powerful and provides more advanced features with built-in functions like text(), position(), and contains().
In real use cases, it's important to note that you're not limited to using just one method. Based on your project requirements, consider utilizing both approaches so that you can maximize their benefits and achieve optimal results!
