
3 Ways to Bypass CAPTCHAs When Web Scraping
Contents
Encountering CAPTCHAs (Completely Automated Public Turing test to tell Computers and Humans Apart) is a common concern among web scrapers. Often used to rate limit scraping from a single source, CAPTCHAs help websites differentiate between people and programs. They do this by presenting a challenge that is simple to humans, but difficult for machines to complete.
Less intrusive forms of user validation—such as Google’s reCAPTCHA—mean you may not encounter as many CAPTCHAs as in the past. Even so, they’re common enough that they can be a hindrance when extracting data.
So how can you avoid or bypass them to ensure your automation goes on without a hitch? In this article, we’ll discuss your options.
What are CAPTCHAs?
CAPTCHAs are security measures designed to tell humans and computers apart. They can take the form of text challenges, image puzzles, or audio prompts, among others.



While some sites still use older forms of CAPTCHAs, they’re gradually being replaced by modern and less intrusive types. These newer versions detect bots with methods such as monitoring cursor movement, reducing friction in the user experience.
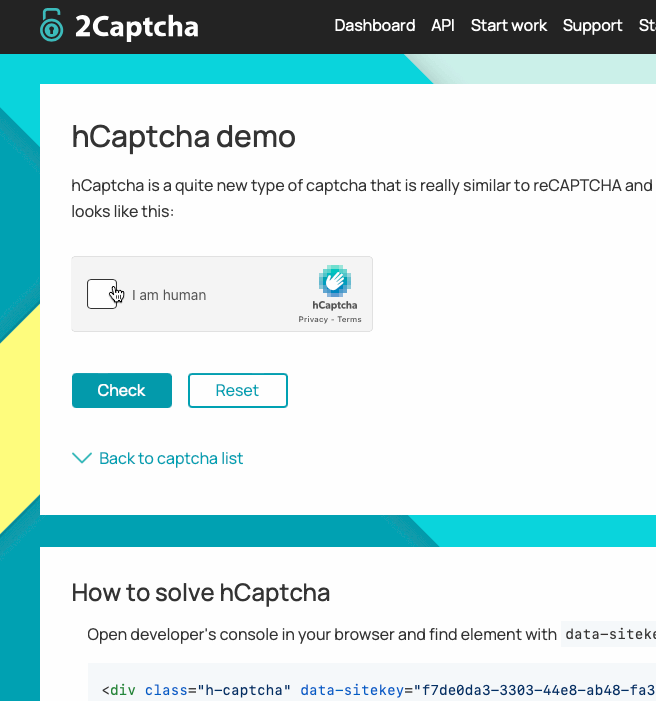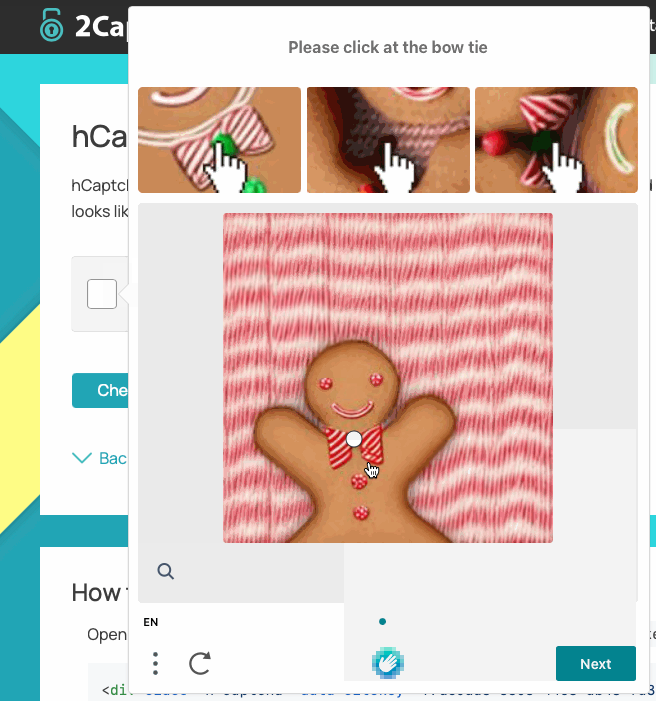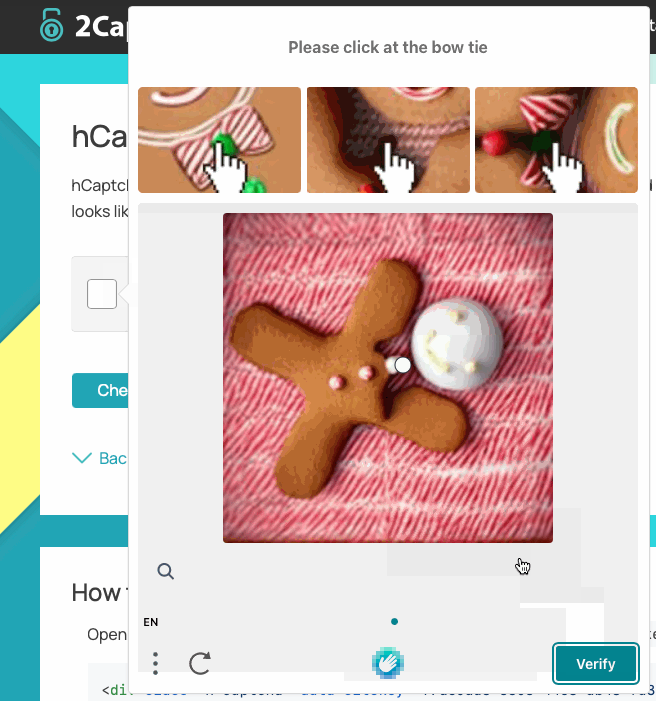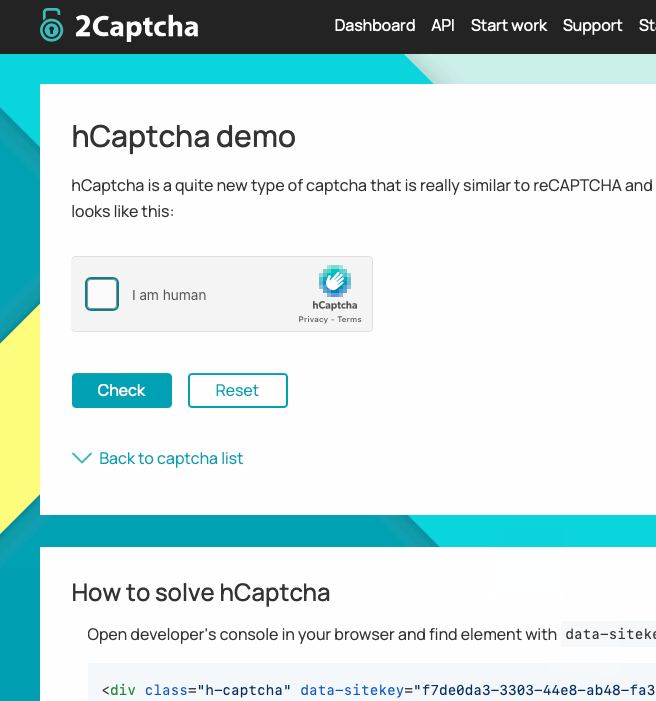
There are a variety of CAPTCHA service providers, but two in particular are worth mentioning:
- hCaptcha: Intuition Machine’s hCaptcha product has a variety of CAPTCHA types, including checkboxes and image puzzles.
- reCAPTCHA: Google’s free CAPTCHA service, reCAPTCHA, is popular among website owners because it’s free-of-use and easy to set up. Their newest version, v3, is completely invisible and requires no input from the user.
Both services regularly maintain and update their products, meaning that any automated browser tasks involving CAPTCHAs need to be frequently updated too.
Bear Tip 🐻: 2Captcha provides helpful demos of common CAPTCHA types, which can help you identify what you are working with.
How Do CAPTCHAs Affect Web Scraping?
Web scrapers access the data on a website by parsing the HTML and navigating the elements on the page. CATCHAs are built to hinder bots and scripts from accessing site content, and they can stop the scraping process.
Many sites continue to monitor sessions even after initial verification. Unusual actions like rapid clicks and skyrocketing page views can raise flags and cause the website to block your access.
On Browserbear, blocked site access usually presents as a failed task with an error message indicating a connection fail.
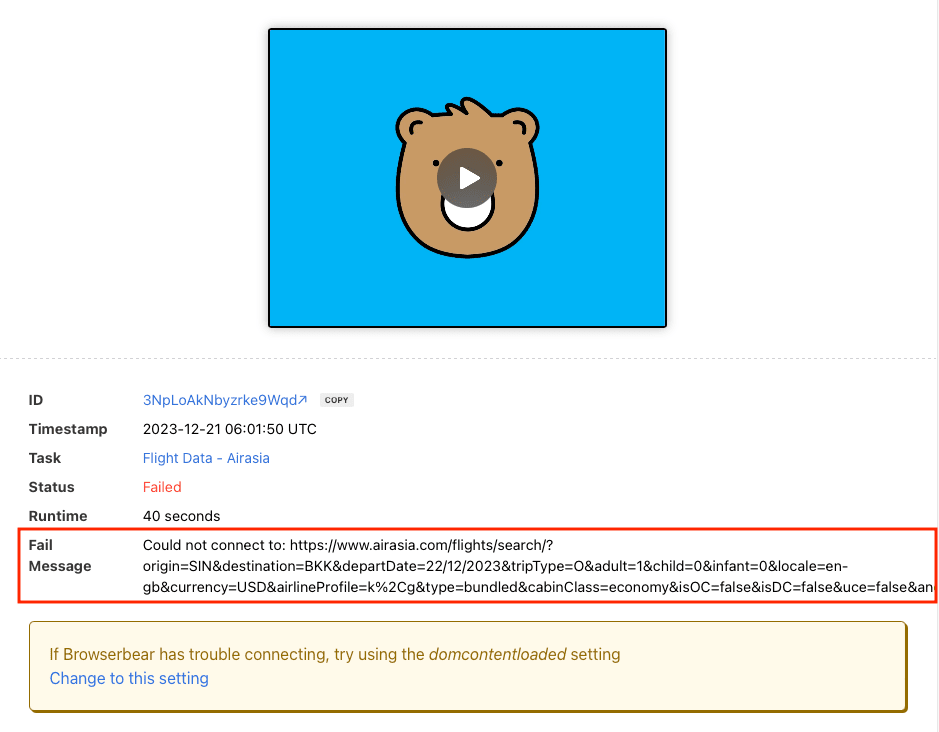
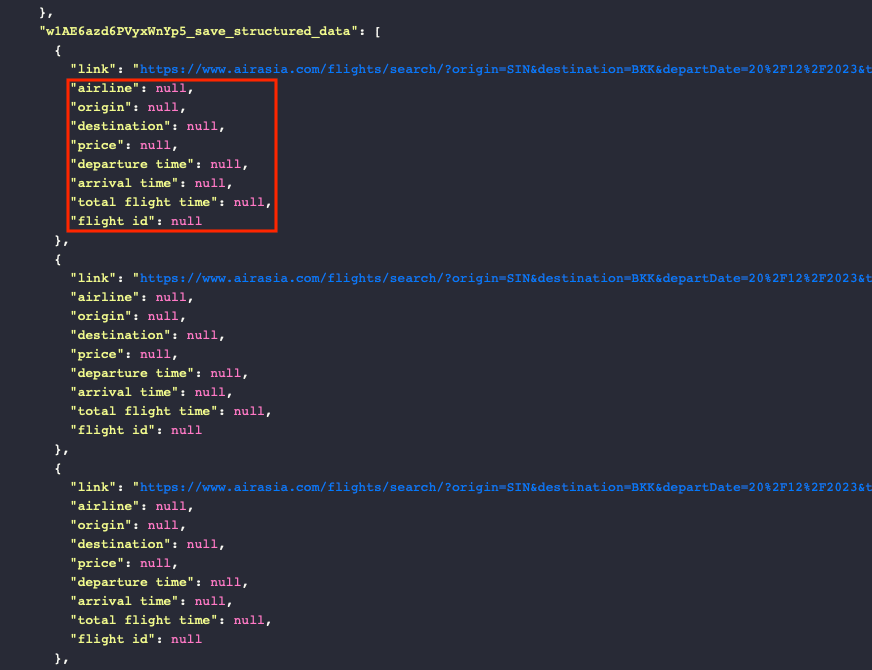
However, there are other possible indications of a block, such as a successful task run with null extracted values. This suggests access might have been revoked while the site was loading.
You can use a variety of techniques to get around CAPTCHAs when extracting data. The method you choose will depend on the specific type of CAPTCHA and the tools you have at your disposal.
Bear Tip 🐻: Before extracting data from a website, be aware of its terms of service and privacy policy. It’s always safest to scrape from public, open-source sites that permit users to extract and use data as they see fit.
Effective Techniques for Bypassing CAPTCHAs
In order to maximize successful web scraping task runs, it’s crucial to establish effective procedures for handling CAPTCHAs. Building a bulletproof workflow and keeping it updated is key to ensuring data gathering is consistent and uninterrupted.
There are many methods you can use to deal with CAPTCHAs when web scraping. Let’s explore three techniques worth considering:
1 - Rotate IP Addresses and User Agents
A rotating proxy server assigns different IP addresses for every connection request, preventing sites from identifying a consistent pattern of requests.
In the way, randomizing user agent strings provide variation to your scraping requests and help avoid detection by invisible CAPTCHAs. These are often triggered by the detection of consistent user agent strings, which are commonly with automated scraping.
2 - Utilize a CAPTCHA Solver
Several third-party service providers can help you automatically solve CAPTCHAs using a variety of methods such as Optical Character Recognition (OCR), advanced algorithms, and machine learning. Other services, like 2Captcha, have a team of humans available to manually solve the challenge and submit results in mere seconds.
There are options for different budget levels and technical expertise. Most of these services require an API integration and are paid products, but they can be incredibly helpful if you encounter certain types of CAPTCHAs frequently.
3 - Mimic Human Behavior
The best way to avoid being flagged as a bot is to not act like a program in the first place. Simulating human-like browsing behavior—such as natural mouse movements, clicks, and scrolling—can make your scraping activities appear organic. This can help bypass invisible CAPTCHAs that are triggered by bot-like site interaction.
Browser automation tools and libraries can help you mimic human behavior by adding delays between requests, randomizing user agent strings, using cookies, and more.
Headless browsers such as Selenium and Puppeteer are popular among developers due to their cost-free availability and ability to provide precise control over browser actions. Non-technical users can also take advantage of nocode browser automation tools like Browserbear.

How to Choose the Best CAPTCHA Solver
If you’re using a CAPTCHA solver, it’s important to select a service provider that meets your specific needs. Some factors you might consider include:
- Supported CAPTCHA Types : Not all service providers are able to support every CAPTCHA type. It’s best to determine what you’re working with and choose a solver that specializes in what you frequently encounter.
- Integration : Most solvers require an API integration, which can be challenging for non-technical folks. Look for an option with onboarding that suits your level of technical expertise, and consider your existing web scraping workflow for best results.
- Pricing : Solver rates can vary, with some providers charging per-item and others opting for a tiered usage model. Evaluate your budget and choose an option that aligns, keeping scalability in mind.
- Support and Documentation : Even the best CAPTCHA-solving algorithm is useless if users can’t easily integrate it into their workflows. Look for an option with comprehensive documentation and support resources, as this will help troubleshoot and resolve issues that will inevitably arise during usage.
You might find it helpful to try out a few different CAPTCHA servers to compare their performance and determine what best meets your specific requirements.
Bear Tip 🐻: Browserbear has a built-in Solve Captcha action for reCAPTCHA v2 and hCaptcha. This functionality is supported by 2Captcha, a human-powered third-party site that helps you gain access to bot-protected sites.
Navigate CAPTCHAs Easily While Scraping
Preventing CAPTCHAs from affecting web scraping reliability can be challenging, but possible with the right precautions. Rotating IP addresses, using solver tools, and mimicking human behavior all contribute to a more organic browsing experience, which helps you fly under the bot-detection radar. Implementing these techniques will maximize your chances of success and ensure your data extraction processes go on without a hitch.
