
How to Scrape Data from a Website Using Browserbear (Part 2)
Contents
In How to Scrape Data from a Website Using Browserbear (Part 1), we have introduced Browserbear as a powerful browser automation tool and showed you how to set up a Browserbear task to scrape data from a website.
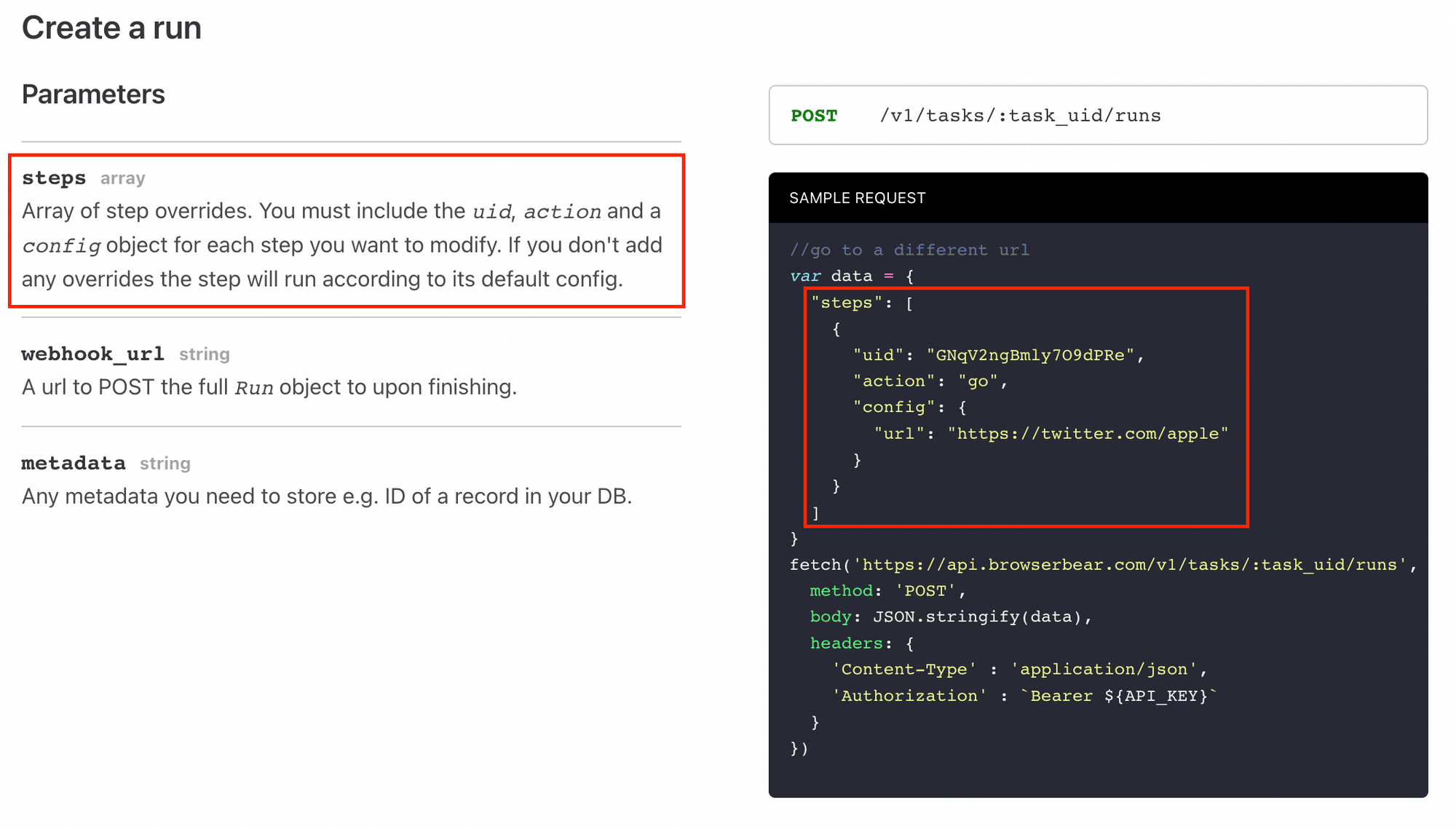
Now that you have a basic understanding of web scraping using Browserbear, it's time to dive deeper into its capabilities. In this article, we will focus on more advanced techniques for scraping data from websites, which include using the data from one task to override the configuration of another task and combining the results of the two tasks.
We will use the same task from Part 1 to scrape the links and other information from the job board, and then go to the link of each job to scrape more information about the particular job.

If you're ready to take your web scraping skills to the next level, let's get started with Part 2 of our Browserbear web scraping tutorial!
Creating a Browserbear Task
The task from Part 1 will scrape the job title, company, location, salary, and link to the job from the job board. To scrape more information about the job when you click on the job title, we will need to create a new task that will go to the job's URL and save the information as structured data.
The steps will be similar to the previous task except that the data selected will be different. We will also override the original URL when we call the API to run the task.
Step 1. Create a Task
After logging in to your account, go to Tasks and create a new task.
Enter a name for your task and click the “Save” button.
Step 2. Add Steps - Go to URL
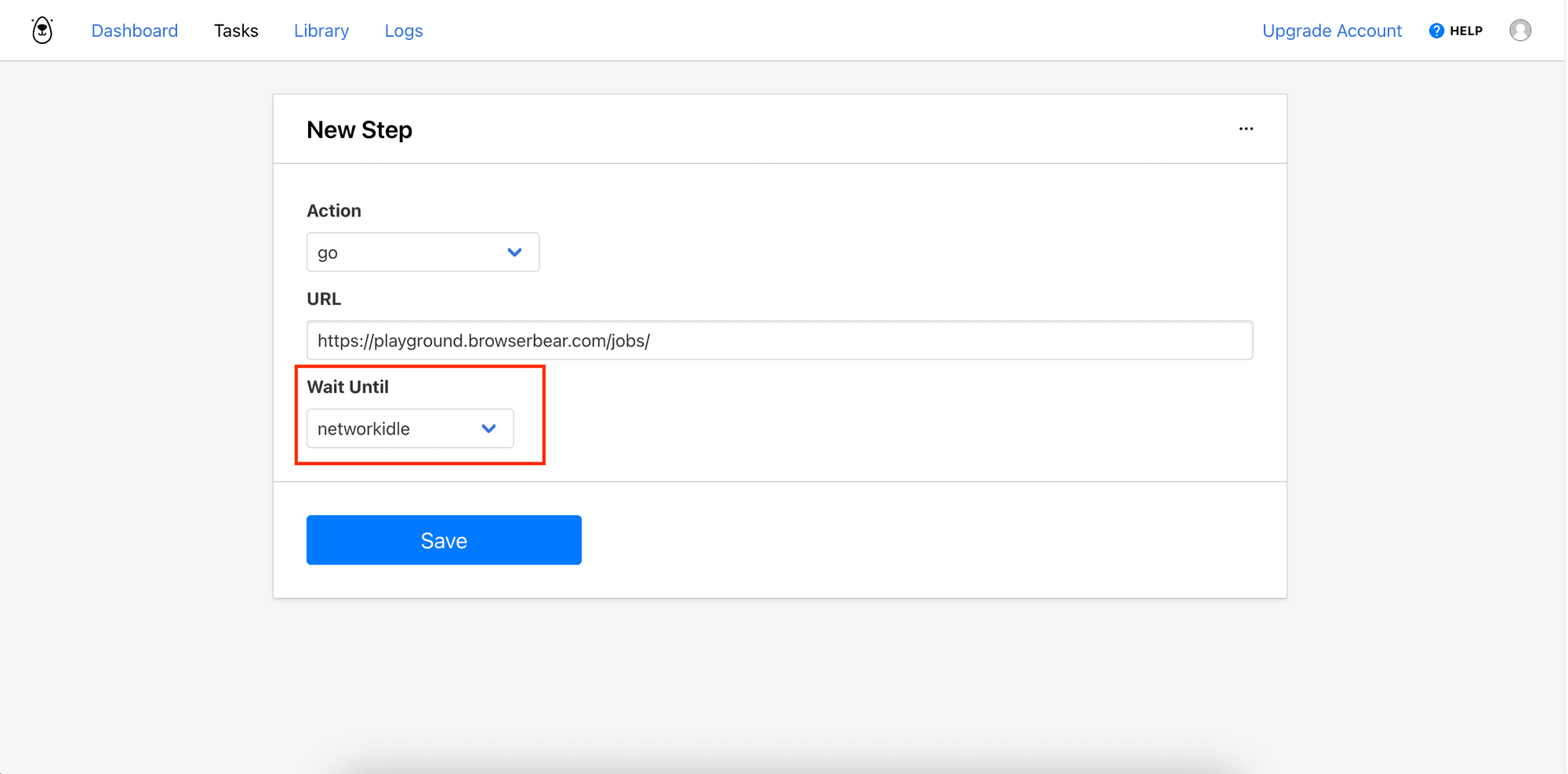
Click “Add Step” to add your first step. Then, select “go” from the Action dropdown and enter the URL of any job from the job board.
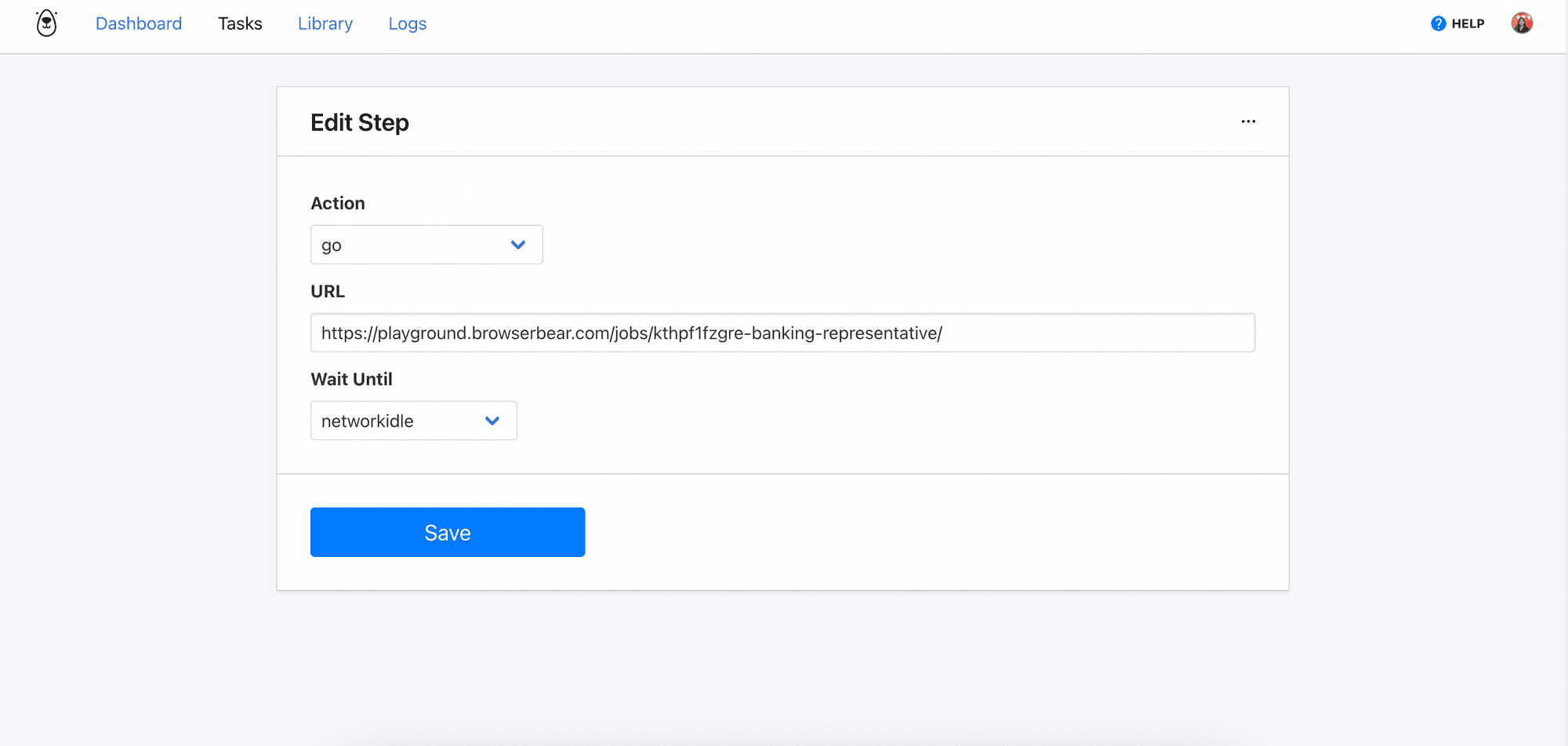
As we want to scrape the detailed information from each job, we will use this task to visit multiple different URLs. We can do this by sending the "Go" step's configuration with a new URL in the request body every time we call the API. This will override the original URL.
For the Wait Until option, select “networkidle” so that the next step will only be triggered when no new network request is made for 500ms.
Save the step and you will be brought to the previous page.
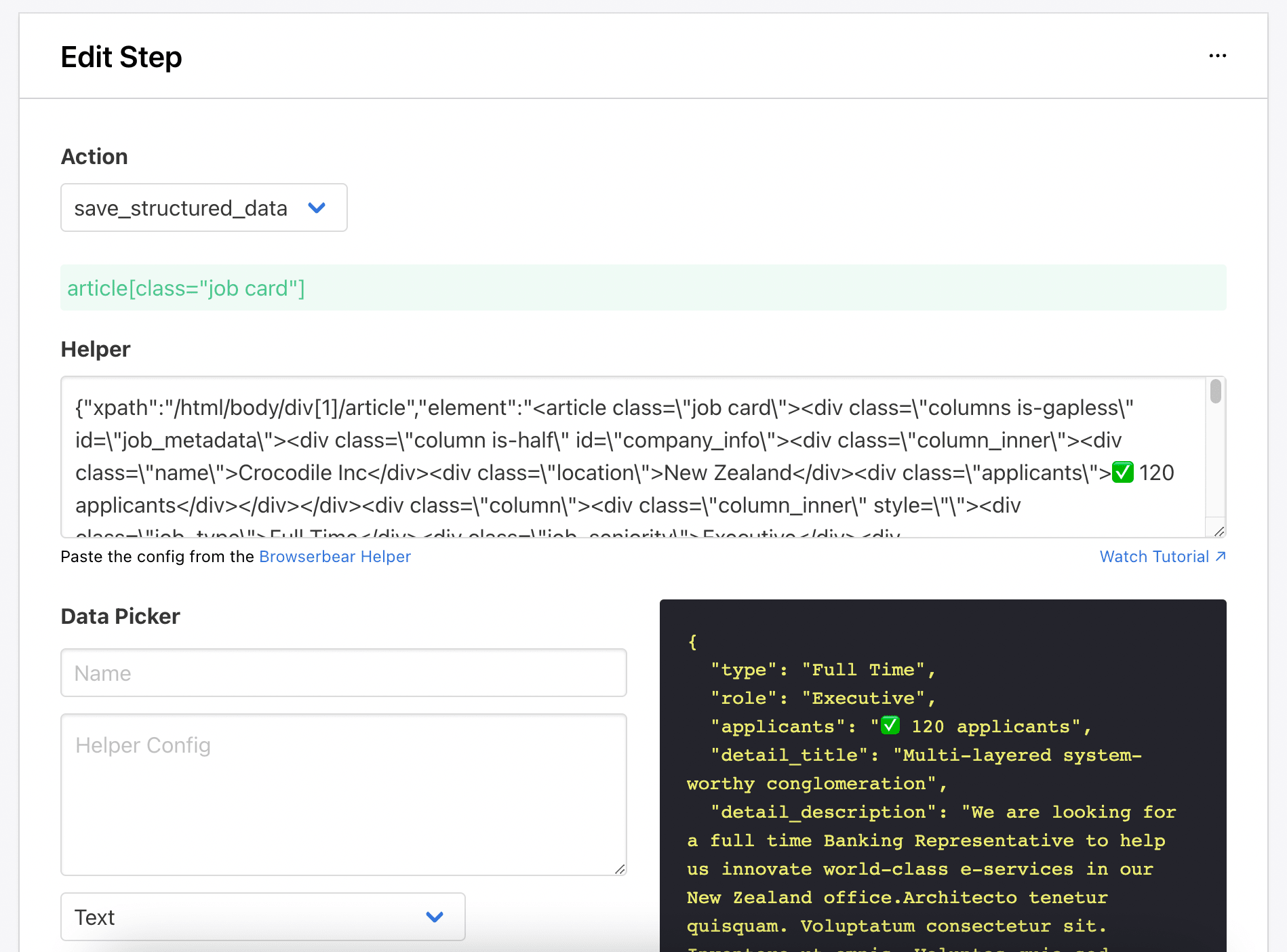
Step 3. Add Steps - Save Structured Data
For this task, we will save the type, role, number of applicants, and the title and description of the job detail. Follow the same steps from Part 1 to select the data using the Browserbear Helper Chrome extension.

Check the selected data in the preview panel and click the “Save” button to save the step.
Step 4. Run the Task
Click “Run Task” to test the data scraping task. You will see the task running when you scroll to the bottom of the page.
Step 5. View the Log/Result
When the task has finished, you can click on the “Log” button to view the result.
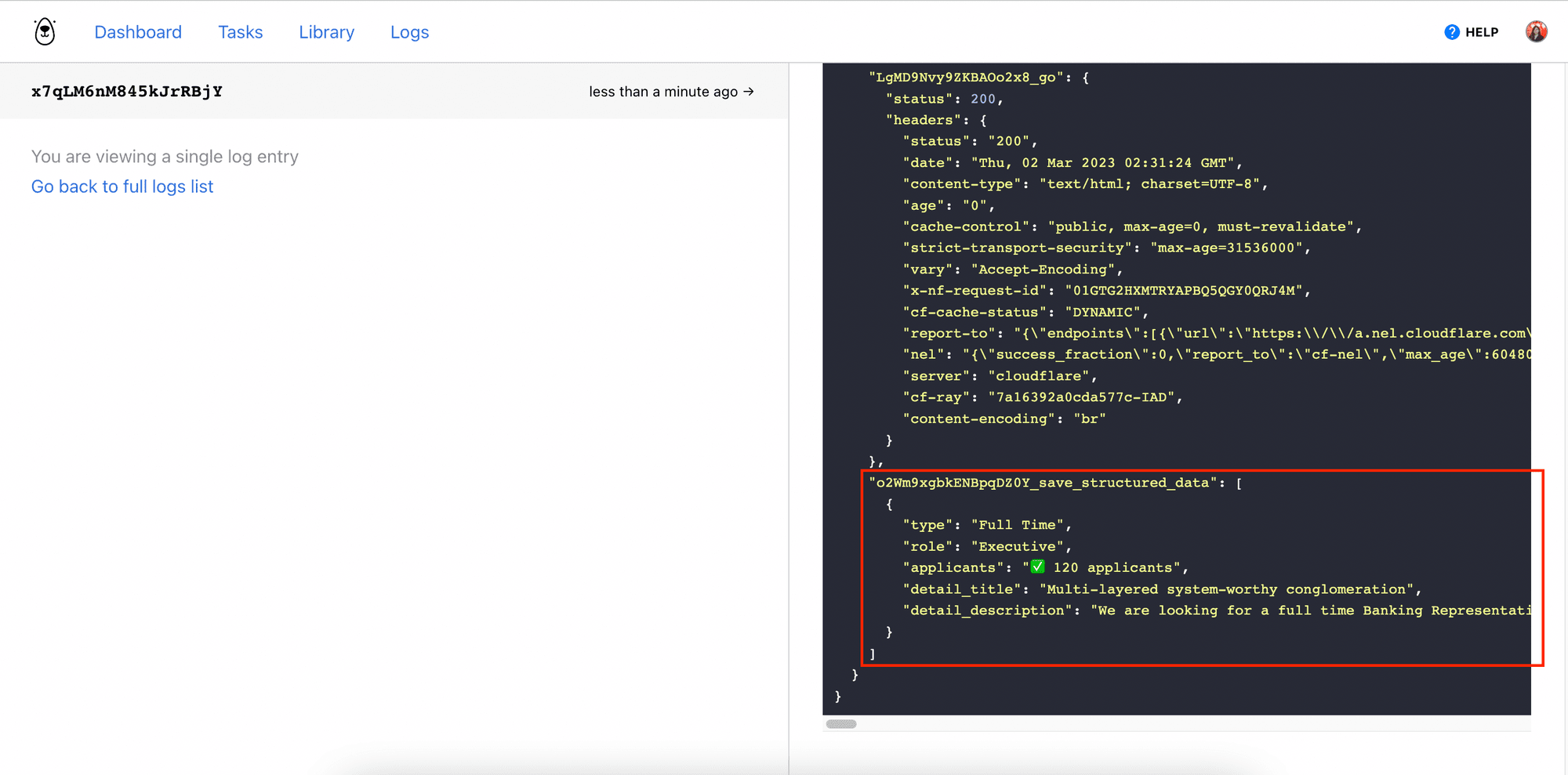
You should only have one object in the result array of the “Save Structured Data” step:
Now that the task can be run successfully, we can write code to run the first task and then visit the scraped links to scrape more information using this task.
Writing the Code to Run the Tasks
We will make some modifications to the code from Part 1 to integrate this new task into the data scraping process. This will be the flow:
1-Run Task 1 to scrape the link and other information
2-Receive the result via API polling
3-Run Task 2 to scrape more information about a particular job
4-Receive the result via API polling
5-Combine the results and export them to a file
Step 1. Import Libraries and Declare Constants
Import fs and declare the API Key, task IDs, and step IDs.
const fs = require('fs');
const API_KEY = "your_api_key";
const FIRST_TASK = {
ID: "first_task_id",
SAVE_STRUCTURED_DATA_STEP_ID: "first_task_save_stuctured_data_id"
};
const SECOND_TASK = {
ID: "second_task_id",
GO_STEP_ID: "second_task_go_id",
SAVE_STRUCTURED_DATA_STEP_ID: "second_task_save_stuctured_data_id"
};
Step 2. Run the First Task
In a self-invoking function, run the first task and receive the result by calling the triggerRun function with the IDs of the task and the “Save Structured Data” step.
(async() => {
// Trigger the first run
const scrapedData = await triggerRun(FIRST_TASK.ID, FIRST_TASK.SAVE_STRUCTURED_DATA_STEP_ID);
})();
The triggerRun function can be used to run different tasks and receive the results of the “Save Structured Data” step. It will call runTask to run the task and getRun to check for the result at an interval of one second. When the task has finished running, it will stop calling the API and return the scraped data.
async function triggerRun(taskId, saveStructuredDataId, body){
return new Promise(async resolve => {
const run = await runTask(taskId, body);
if(run.status === "running" && run.uid){
console.log(`Task ${run.uid} is running... Poll API to get the result`);
const polling = setInterval(async () => {
const runResult = await getRun(taskId, run.uid);
if(runResult.status === "running") {
console.log("Still running.....")
} else if (runResult.status === "finished") {
const structuredData = runResult.outputs[`${saveStructuredDataId}_save_structured_data`];
clearInterval(polling);
resolve(structuredData);
}
}, 1000)
}
})
}
The runTask function will make a POST request to the Browserbear API to execute the run.
async function runTask(taskId, body) {
const res = await fetch(`https://api.browserbear.com/v1/tasks/${taskId}/runs`, {
method: 'POST',
body: body,
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${API_KEY}`,
},
});
return await res.json();;
}
The getRun function will make a GET request to the Browserbear API to check the status and get the result of the run.
async function getRun(taskId, runId) {
const res = await fetch(`https://api.browserbear.com/v1/tasks/${taskId}/runs/${runId}`, {
method: 'GET',
headers: {
Authorization: `Bearer ${API_KEY}`,
},
});
const data = await res.json();
return data;
}
The result returned and saved to structuredData should contain the data below:
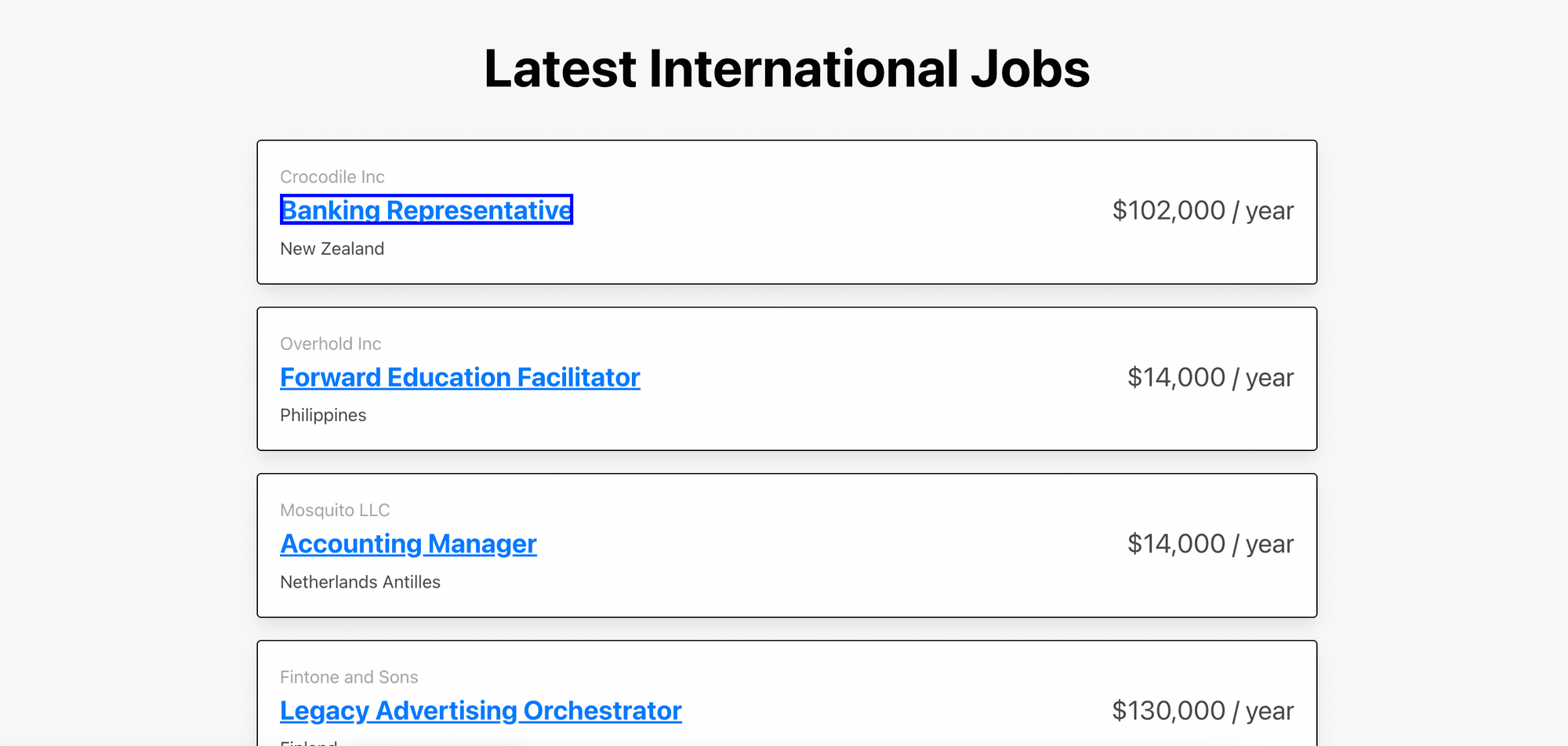
[
{
"job_title": "Banking Representative",
"company": "Crocodile Inc",
"location": "New Zealand",
"salary": "$102,000 / year",
"link": "/jobs/KTHPf1FzgRE-banking-representative/"
},
{
"job_title": "Forward Education Facilitator",
"company": "Overhold Inc",
"location": "Philippines",
"salary": "$14,000 / year",
"link": "/jobs/WY9qcPIiBtE-forward-education-facilitator/"
},
{
"job_title": "Accounting Manager",
"company": "Mosquito LLC",
"location": "Netherlands Antilles",
"salary": "$14,000 / year",
"link": "/jobs/P_XdUn35VCY-accounting-manager/"
}
...
]
Step 3. Run the Second Task
In the self-invoking function, get the full job detail by calling getFullJobDetail with the scraped data.
(async() => {
// Trigger the first run
const scrapedData = await triggerRun(FIRST_TASK.ID, FIRST_TASK.SAVE_STRUCTURED_DATA_STEP_ID);
// Trigger the second run (Part 2): visit the job links from the first run and scrape the details of a particular job
const fullJobDetail = await getFullJobDetail(scrapedData);
})();
The getFullJobDetail function will go through all the jobs and go to the link of each job to scrape more information—which is done by running the second task.
async function getFullJobDetail(scrapedData){
return await Promise.all(scrapedData.map(async job => {
const data = {
"steps": [
{
"uid": SECOND_TASK.GO_STEP_ID,
"action": "go",
"config": {
"url": `https://playground.browserbear.com${job.link}`
}
}
]
};
const jobDetail = await triggerRun(SECOND_TASK.ID, SECOND_TASK.SAVE_STRUCTURED_DATA_STEP_ID, JSON.stringify(data));
return {
...job,
...jobDetail[0]
}
}))
}
When you make a POST request to the Browserbear API with a request body, it will override the original config. In this case, the URL of the “Go” step will be replaced by the link of each job.
const data = {
"steps": [
{
"uid": SECOND_TASK.GO_STEP_ID,
"action": "go",
"config": {
"url": `https://playground.browserbear.com${job.link}`
}
}
]
};
Call triggerRun with the IDs needed and the config above. You should get this result and it will be assigned to jobDetail:
[
{
"type": "Full Time",
"role": "Executive",
"applicants": "✅ 120 applicants",
"detail_title": "Multi-layered system-worthy conglomeration",
"detail_description": "We are looking for a full time Banking Representative to help us innovate world-class e-services in our New Zealand office.Architecto tenetur quisquam. Voluptatum consectetur sit. Inventore ut omnis. Voluptas quia sed. Consequatur eveniet voluptatem. Amet dolorem explicabo. Et omnis accusamus. Provident qui aperiam. Aperiam perspiciatis hic. Quia est repellendus. Amet beatae consequuntur.Dolore ea expedita. Incidunt magnam fuga. Sed earum et. Omnis eos et. Officia laudantium ea. Necessitatibus itaque ullam. Laudantium cupiditate molestiae. Nisi excepturi dolorum. Explicabo eaque et. Molestiae accusantium omnis. Non fugiat possimus. Possimus iusto dolore. Sit nemo exercitationem. Tenetur qui quia. Ut earum aliquid.Rerum unde voluptate. Maxime totam id. Quasi id culpa. Sit enim est. Est nobis ratione. Minima deleniti et. Et sed recusandae. Vel esse explicabo. Necessitatibus ut accusamus. Nisi veritatis assumenda. Esse non et.Quisquam iure illo. Totam eos ipsum. Aut est eos. Quas ad et. Saepe ut aut. In itaque at. Architecto aspernatur maxime. Deleniti ullam laudantium. Vel velit vitae. Perspiciatis voluptas sint. Sequi cum totam. Ratione deserunt non. Consequuntur et quod.Et facilis aut. Sint asperiores tenetur. Exercitationem accusantium qui. Libero aperiam non. Est rerum assumenda. Praesentium doloremque iste. Ut sunt omnis. Iste commodi et. Officia fuga itaque. Deleniti facilis itaque. Ea ab impedit. Provident repellendus quia. Provident voluptates assumenda. Enim aut cupiditate. Consequatur molestias consequatur.Apply Now"
}
]
We will add it to the result from the first task and return the combined result:
return {
...job,
...jobDetail[0]
}
Step 4. Export the Result to a File
Finally, add writeToFile(fullJobDetail) to the self-invoking function to export the data to a JSON file.
(async() => {
// Trigger the first run
const scrapedData = await triggerRun(FIRST_TASK.ID, FIRST_TASK.SAVE_STRUCTURED_DATA_STEP_ID);
// Trigger the second run (Part 2): visit the job links from the first run and scrape the details of a particiular job
const fullJobDetail = await getFullJobDetail(scrapedData);
writeToFile(fullJobDetail);
})();
function writeToFile(data) {
fs.writeFile('result.json', JSON.stringify(data), function(err) {
if (err) {
console.log(err)
}
})
}
In the result.json file, you should have the complete information about each job from the two tasks.
[
{
"job_title": "Banking Representative",
"company": "Crocodile Inc",
"location": "New Zealand",
"salary": "$102,000 / year",
"link": "/jobs/KTHPf1FzgRE-banking-representative/",
"type": "Full Time",
"role": "Executive",
"applicants": "✅ 120 applicants",
"detail_title": "Multi-layered system-worthy conglomeration",
"detail_description": "We are looking for a full time Banking Representative to help us innovate world-class e-services in our New Zealand office.Architecto tenetur quisquam. Voluptatum consectetur sit. Inventore ut omnis. Voluptas quia sed. Consequatur eveniet voluptatem. Amet dolorem explicabo. Et omnis accusamus. Provident qui aperiam. Aperiam perspiciatis hic. Quia est repellendus. Amet beatae consequuntur.Dolore ea expedita. Incidunt magnam fuga. Sed earum et. Omnis eos et. Officia laudantium ea. Necessitatibus itaque ullam. Laudantium cupiditate molestiae. Nisi excepturi dolorum. Explicabo eaque et. Molestiae accusantium omnis. Non fugiat possimus. Possimus iusto dolore. Sit nemo exercitationem. Tenetur qui quia. Ut earum aliquid.Rerum unde voluptate. Maxime totam id. Quasi id culpa. Sit enim est. Est nobis ratione. Minima deleniti et. Et sed recusandae. Vel esse explicabo. Necessitatibus ut accusamus. Nisi veritatis assumenda. Esse non et.Quisquam iure illo. Totam eos ipsum. Aut est eos. Quas ad et. Saepe ut aut. In itaque at. Architecto aspernatur maxime. Deleniti ullam laudantium. Vel velit vitae. Perspiciatis voluptas sint. Sequi cum totam. Ratione deserunt non. Consequuntur et quod.Et facilis aut. Sint asperiores tenetur. Exercitationem accusantium qui. Libero aperiam non. Est rerum assumenda. Praesentium doloremque iste. Ut sunt omnis. Iste commodi et. Officia fuga itaque. Deleniti facilis itaque. Ea ab impedit. Provident repellendus quia. Provident voluptates assumenda. Enim aut cupiditate. Consequatur molestias consequatur.Apply Now"
},
{
"job_title": "Forward Education Facilitator",
"company": "Overhold Inc",
"location": "Philippines",
"salary": "$14,000 / year",
"link": "/jobs/WY9qcPIiBtE-forward-education-facilitator/",
"type": "Part Time",
"role": "Intern",
"applicants": "✅ 187 applicants",
"detail_title": "Extended demand-driven algorithm",
"detail_description": "We are looking for a part time Forward Education Facilitator to help us strategize back-end web-readiness in our Philippines office.Perferendis eos maxime. Sapiente saepe placeat. Placeat fuga magni. Cupiditate culpa dolorum. Repellat aliquid eveniet. In ex dolorem. Consectetur impedit rem. Nesciunt ab voluptas. Minus rerum excepturi. Sit ipsum non. Saepe rem accusamus. Possimus et culpa. Voluptas eum molestiae. Est mollitia voluptatibus.Nisi maxime ipsum. Beatae et et. Quo sint delectus. Rerum rem voluptate. Ea et consequatur. Eos quis odit. Magni qui quia. Qui corrupti quia. Eius temporibus et. Et debitis voluptatum. In voluptatem dolorem. Voluptas nam modi. Incidunt earum distinctio. Qui nemo temporibus. Fuga dolore in.Voluptatem id sint. Quia nesciunt impedit. Voluptas placeat vero. Consequatur id ullam. Alias maiores ipsum. Aut id at. Ea consectetur quis. Ut et quidem. Aut maxime soluta. Porro blanditiis earum. Ipsam vitae veritatis. Iure blanditiis et.Qui minus pariatur. Quisquam minima occaecati. Ratione dolor blanditiis. Repudiandae nemo eius. Magnam non ut. Ducimus qui atque. Vel aspernatur nihil. Quaerat veritatis vitae. Vel magni sed. Iure qui soluta. Possimus dignissimos nisi.Quis eos molestias. Quia officia possimus. Occaecati incidunt dignissimos. Eum doloribus omnis. Ab et quo. Et quibusdam necessitatibus. Distinctio nostrum nihil. Totam recusandae quibusdam. Ipsa minus aperiam. Eum laboriosam nihil. Et nisi earum.Apply Now"
}
...
]
🐻 View the full code and result on GitHub.
Conclusion
With the vast amounts of data available on the web, web scraping can be an incredibly valuable skill to have. With Browserbear, you can scrape data from websites and automate it easily, saving you time and effort in the process.
Besides scraping data from websites, you can also use Bannerbear to automate form submission, check an HTML element, take a screenshot, and more. If you haven’t registered a Browserbear account, make sure to sign up for a free trial now to explore Browserbear's capabilities and discover how it can help you to simplify work using automation.
